Data Lake e Delta Lake, você sabe a diferença?
Se você atua na área de ciência de dados ou tecnologia em geral já deve ter ouvido falar do “Data Lake” ou “Lago de Dados”, correto?
E sobre o “Delta Lake”? Já ouviu dizer? Bom aos que já ouviram dizer parabéns, estão super atualizados com as novidades da área!
Hoje vou falar sobre estas duas arquiteturas de armazenamento de dados e buscar esclarecer mediante a exemplos práticos de ambiente de negócios, quando precisamos mesmo de uma arquitetura mais complexa ou uma mais simples já atenderia muito bem às necessidades da empresa.
Vamos começar pelo conceito de “Data Lake”, o objetivo principal de uma empresa em criar um ambiente centralizado de dados, é garantir a qualidade e segurança dos dados coletados e armazenados pela empresa.
Empresas que já aderiram a tomada de decisões baseada em dados precisam ter a certeza de que todas as áreas estão se baseando no mesmo nível de informação. Ou seja, de fontes confiáveis e sobre a mesma base histórica. Quem já não participou de uma reunião onde duas áreas divergem sobre o resultado de um mesmo indicador?
A arquitetura básica, ou seja, independentemente do fornecedor de serviços de nuvem, infraestrutura de hardware e software utilizados seguem os parâmetros a seguir:

Como podem ver, podemos ter dados de diferentes fontes, sejam elas de bancos de dados relacionais ou não relacionais, como captura de imagem ou mensageria de objetos inteligentes (IoTs), arquivos capturados da internet ou de sistemas de e-mails, etc.
Todos são direcionados para o mesmo ambiente, onde passam por uma “triagem”, a classificação de dados sensíveis por exemplo, tornar anônimo quando necessário, depois passam por uma etapa de qualificação dos dados, campos válidos, campos nulos. Uma vez validados podem ser enriquecidos com o cruzamento de informações, e por fim estarão catalogados e disponíveis para consumo.
Neste processo, como podem ver, temos e etapas de tratamento para enfim disponibilizar os dados para utilização. Estas etapas consomem não somente horas de trabalho dos engenheiros de dados como também horas de processamento e armazenamento, consequentemente aumento de custos e demora na disponibilização dos dados para consumo.
Na arquitetura “Delta Lake”, o foco é otimizar esse processo de coleta e tratamento dos dados, encurtando o tempo de processamento e descartando o que não for útil para também economizar no armazenamento.
Vamos detalhar um pouco como isso ocorre:
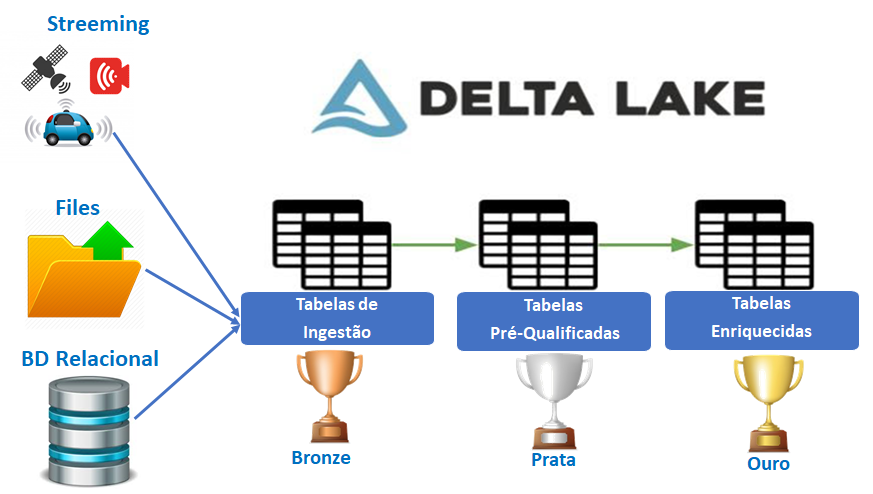
O Delta Lake é uma camada de armazenamento de software livre que traz confiabilidade para os data lakes. O Delta Lake fornece transações ACID, tratamento de metadados escalonáveis e unifica o processamento de dados de lote e streaming.
Vamos exemplificar como a utilização de transações ACID(Atomicity, Consistency, Isolation, Durability — acrônimo de Atomicidade, Consistência, Isolamento e Durabilidade:
1. Vamos usar o caso hipotético de um aplicativo de mobile-banking. O cliente aciona a consulta de saldo, essa solicitação chega ao “Delta Lake” do banco;
2. Primeiro, ele cria uma tabela nova em um banco de dados (Bronze);
3. Em seguida, ele chama um objeto especializado para coletar, formatar e inserir dados na nova tabela. Essas duas tarefas estão relacionadas e até mesmo interdependentes, que você deseja evitar a criação de uma nova tabela, a menos que você possa preenchê-lo com dados. Ambas as tarefas dentro do escopo de uma única transação em execução impõem a conexão entre elas. Se a segunda tarefa falhar, a primeira tarefa será revertida para um ponto antes que a nova tabela foi criada (Prata);
4. Para garantir um comportamento previsível, todas as transações devem ter as propriedades básicas de ACID. Essas propriedades reforçam a função de transações de missão crítica como propostas de tudo ou nada, ou seja, ACID garante que um conjunto de tarefas relacionadas obtiveram êxito ou falharam como uma unidade.
5. No exemplo, para que haja uma transação de confirmação, todos os participantes devem garantir que qualquer alteração nos dados será permanente. As alterações devem persistir mesmo que haja falhas do sistema ou outros eventos imprevisíveis. Se até mesmo um único participante não fizer essa garantia, a transação inteira falhará. Todas as alterações de dados dentro do escopo da transação serão revertidas para um ponto específico do conjunto.
6. Finalizando o exemplo, se todo processo de validação for confirmado, o cliente receberá a resposta de saldo, e todas as informações ficarão gravadas corretamente no banco de dados “Ouro”, de informações validadas e aptas para consumo;
Com essa arquitetura, torna-se viável a utilização de algoritmos estatísticos para análise em tempo real e com menor consumo de processamento e armazenamento.
A solução foi desenvolvida como código aberto e é fundamentada no ambiente Apache/Spark.
Aqui buscamos apenas apresentar de forma bem simples as vantagens para que gestores possam avaliar esta possibilidade técnica de automação de processos com vantagens de velocidade e garantia de qualidade de dados com redução de custos.
Como podem ver, em uma empresa que utiliza dados em tempo real com maior frequência, a arquitetura “Delta Lake” seria ideal, mas para aquelas empresas que possuem grandes volumes de dados mas não necessitam do uso em tempo real, manter na arquitetura tradicional pode ser a melhor solução.
Sendo assim, acredito que agora ficou mais claro quando optar por uma ou outra solução, na lista de fontes do artigo seguem alguns sites com detalhamento técnico.
Fontes:
· Site Aprendizagem de Máquina — https://aprendizadodemaquina.com/artigos/data-lake-vs-delta-lake/
· Site Delta.io : https://delta.io/
· Databricks: https://docs.databricks.com/delta/delta-intro.html
· Talend: https://www.talend.com/resources/databricks-integration/
A autora:
· Embaixadora da Stanford University para o projeto Women In Data Science — WIDS;
· Voluntária Grupo Mulheres do Brasil;
· Especialização em Gestão de Dados (CDO Foundations) pelo MIT — Massachusetts Institute of Technology — EUA;
· Mestrado em Adm. Empresas pela FGV;
· Graduada em Adm. Empresas pela FAAP;
· Professora Universitária no SENAC para os cursos de Pós-Graduação em BIG Data e Gestão do Conhecimento e Inovação e para os cursos de graduação a Distância do SENAC;
· Autora dos livros:
. A Atuação do Profissional de Inteligência Competitiva, Publicit, 2015
. Pesquisa de Marketing, Série Universitária, SENAC, 2017
· Liderança/Participação em Comunidades Digitais: Women In Blockchain, ABINC Data & Analytics, FINTECHs & Newtechs, Marco Civil IA
· Empreendedora na Consultoria estratégica Analytics Data Services;
· Atuação como executiva nas áreas de planejamento estratégico de marketing e gestão e governança de dados em empresas como Unisys, Teradata, Santander, IBM dentre outras
** Este texto não reflete, necessariamente, a opinião da Escola de IA
Tag:#bigdata, #datalake, #deltalake
Você poderá gostar


Episódio #8 – Podcast IA, Bancos e Fintechs
